

How To Merge Data Sets In R
This article is also available in Castilian.
Merging—also known as joining—two datasets by ane or more common ID variables (keys) is a common task for any data scientist. If y'all get the merge wrong you can create some serious harm to your downstream analysis so you'd meliorate make sure you're doing the correct affair! In order to practice so, I'll walk you through three different approaches to joining tables in R: the {base of operations} way, the {dplyr} way and the SQL mode (yes, you can use SQL in R).
Types of Merges
Offset of, though, permit'southward review the different ways you can merge datasets. Borrowing from the SQL terminology I will cover these 4 types:
- Left join
- Right bring together
- Inner join
- Full join
Left Join
In a left bring together involving datasets L and R the final table—permit'due south call it LR—will contain all records from dataset L simply only those records from dataset R whose key (ID) is independent in L.
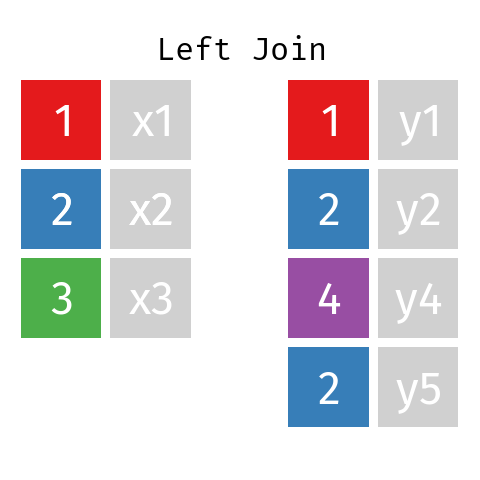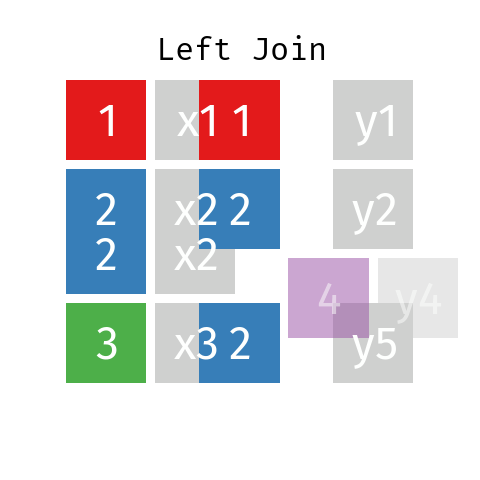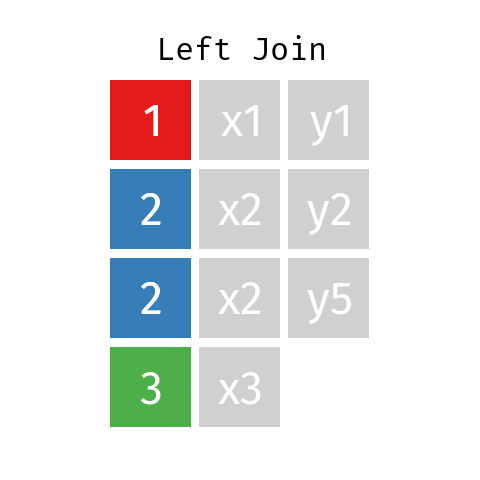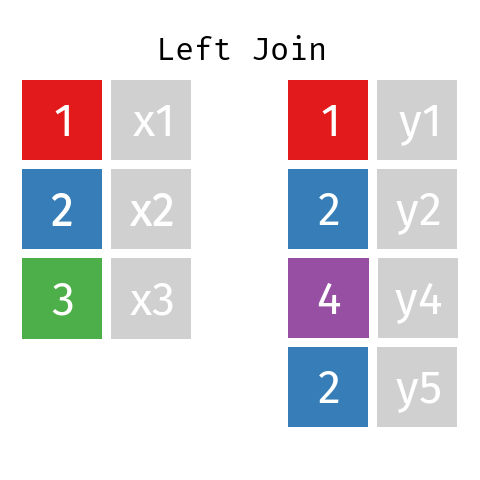
Right Bring together
A right join is just like a left join simply the other way around: the concluding table contains all rows from R and just those from L with a matching fundamental. Notation that you can re-write any right bring together of 50 with R as a left join of R with 50.

Inner Join
In an inner join only those records from L and R who take a matching key in the other dataset are independent in the final table.

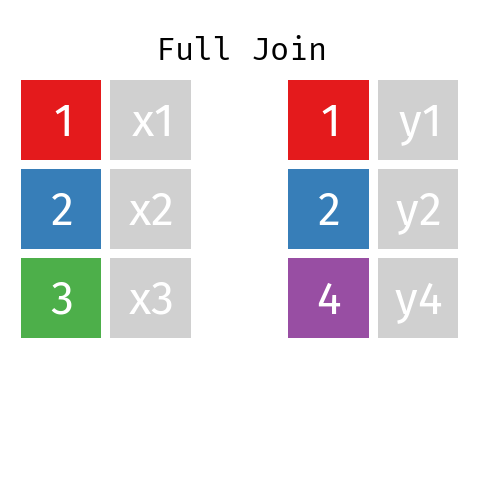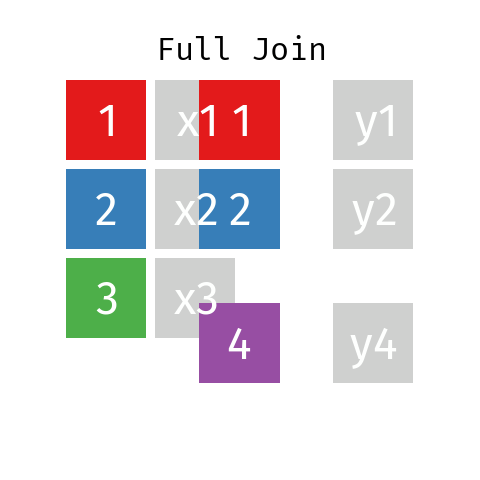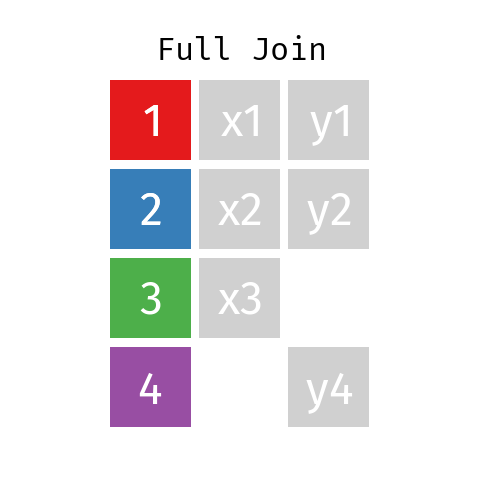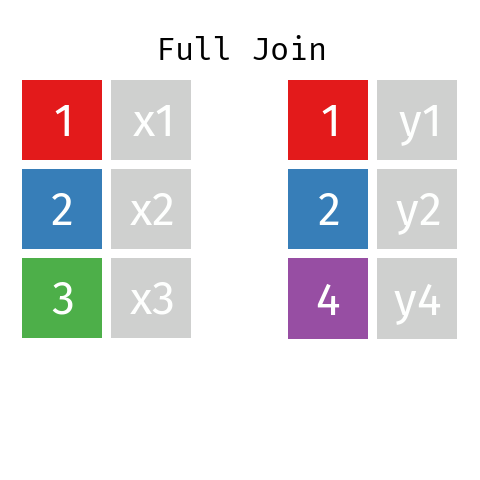
Full Join
By using a full join the resulting dataset contains all rows from L and all rows from R regardless of whether or not there'south a matching central.
The {base} Way
Enough of the theory, permit's explore how to actually perform a merge in R. Showtime of, the {base of operations} fashion. In {base} R you employ a unmarried office to perform all merge types covered above. Conveniently, it is called merge().
To illustrate the concepts I will use 2 fictitious datasets of a clinical trial. One table contains demographic information and the other one adverse events recorded throughout the course of the trial. Notation that patient P2 has a record in demographics but not in adverse_events and that P4 is contained in adverse_events but not in demographics.
demographics <- data.frame ( id = c ( "P1" , "P2" , "P3" ), age = c ( 40 , 54 , 47 ), state = c ( "GER" , "JPN" , "BRA" ), stringsAsFactors = Fake ) adverse_events <- data.frame ( id = c ( "P1" , "P1" , "P3" , "P4" ), term = c ( "Headache" , "Neutropenia" , "Constipation" , "Tachycardia" ), onset_date = c ( "2020-12-03" , "2021-01-03" , "2020-11-29" , "2021-01-27" ), stringsAsFactors = FALSE ) By default, merge() will perform an inner join: only those patients that appear in both the demographics and adverse_events datasets are included in the last table.
merge ( x = demographics, y = adverse_events, by = "id" ) ## id age country term onset_date ## 1 P1 40 GER Headache 2022-12-03 ## 2 P1 40 GER Neutropenia 2022-01-03 ## 3 P3 47 BRA Constipation 2022-11-29 To perform a left join, prepare the all.x parameter to TRUE. For a right bring together practice the aforementioned with the all.y parameter.
merge ( 10 = demographics, y = adverse_events, by = "id" , all.x = Truthful ) ## id age land term onset_date ## 1 P1 40 GER Headache 2022-12-03 ## 2 P1 40 GER Neutropenia 2022-01-03 ## 3 P2 54 JPN <NA> <NA> ## 4 P3 47 BRA Constipation 2022-eleven-29 merge ( 10 = demographics, y = adverse_events, by = "id" , all.y = TRUE ) ## id age country term onset_date ## ane P1 twoscore GER Headache 2022-12-03 ## 2 P1 40 GER Neutropenia 2022-01-03 ## 3 P3 47 BRA Constipation 2022-xi-29 ## iv P4 NA <NA> Tachycardia 2022-01-27 Finally, a total bring together tin can be performed by either setting both all.x and all.y to True or specifying all = TRUE.
merge ( ten = demographics, y = adverse_events, by = "id" , all = TRUE ) ## id age land term onset_date ## 1 P1 40 GER Headache 2022-12-03 ## 2 P1 40 GER Neutropenia 2022-01-03 ## three P2 54 JPN <NA> <NA> ## 4 P3 47 BRA Constipation 2022-11-29 ## 5 P4 NA <NA> Tachycardia 2022-01-27 In the ii example datasets I created, the mutual key is conveniently called id in both tables. However, this doesn't necessarily accept to be the case. If the two datasets you'd like to merge accept dissimilar names for their common ID variables you can specify them individually using the past.x and past.y parameters of merge().
adverse_events2 <- adverse_events colnames (adverse_events2)[ 1L ] <- "pat_id" merge ( ten = demographics, y = adverse_events2, by.x = "id" , by.y = "pat_id" , all = TRUE ) ## id age state term onset_date ## 1 P1 xl GER Headache 2022-12-03 ## 2 P1 40 GER Neutropenia 2022-01-03 ## 3 P2 54 JPN <NA> <NA> ## 4 P3 47 BRA Constipation 2022-xi-29 ## 5 P4 NA <NA> Tachycardia 2022-01-27 The {dplyr} Way
Unlike {base} R—which uses a single function to perform the different merge types—{dplyr} provides one function for each type of join. And fortunately they are named just every bit you'd expect: left_join(), right_join(), inner_join() and full_join(). Personally I'm a big fan of this interface and thus tend to use {dplyr} for joining datasets much more often than {base}.
library (dplyr) left_join(demographics, adverse_events, by = "id" ) ## id historic period state term onset_date ## 1 P1 40 GER Headache 2022-12-03 ## 2 P1 twoscore GER Neutropenia 2022-01-03 ## 3 P2 54 JPN <NA> <NA> ## 4 P3 47 BRA Constipation 2022-11-29 inner_join(demographics, adverse_events, past = "id" ) ## id historic period country term onset_date ## 1 P1 twoscore GER Headache 2022-12-03 ## 2 P1 40 GER Neutropenia 2022-01-03 ## iii P3 47 BRA Constipation 2022-eleven-29 full_join(demographics, adverse_events, by = "id" ) ## id historic period country term onset_date ## 1 P1 40 GER Headache 2022-12-03 ## 2 P1 40 GER Neutropenia 2022-01-03 ## 3 P2 54 JPN <NA> <NA> ## 4 P3 47 BRA Constipation 2022-11-29 ## v P4 NA <NA> Tachycardia 2022-01-27 In case the ID variable names of the two tables do non friction match y'all need to pass a named vector every bit statement to by. The name and value corresponds to the central in the first and second tabular array, respectively.
right_join(demographics, adverse_events2, by = c ( "id" = "pat_id" )) ## id age country term onset_date ## 1 P1 40 GER Headache 2022-12-03 ## 2 P1 40 GER Neutropenia 2022-01-03 ## iii P3 47 BRA Constipation 2022-11-29 ## iv P4 NA <NA> Tachycardia 2022-01-27 The SQL Way
When it comes to merging tables there'due south no way ane cannot mention the structured query language (SQL). In that location are several R packages available from CRAN to straight send SQL queries from R to a database. The {tidyquery} package does something different, though. It takes the SQL query you provide the query() function as input, translates it to {dplyr} code so executes this {dplyr} lawmaking to produce the final consequence.
library (tidyquery) query( "select * from demographics right join adverse_events using(id)" ) ## id age land term onset_date ## one P1 40 GER Headache 2022-12-03 ## ii P1 40 GER Neutropenia 2022-01-03 ## 3 P3 47 BRA Constipation 2022-11-29 ## iv P4 NA <NA> Tachycardia 2022-01-27 query( "select * from demographics inner bring together adverse_events using(id)" ) ## id age country term onset_date ## i P1 40 GER Headache 2022-12-03 ## 2 P1 forty GER Neutropenia 2022-01-03 ## three P3 47 BRA Constipation 2022-11-29 query( "select * from demographics full join adverse_events using(id)" ) ## id age country term onset_date ## 1 P1 forty GER Headache 2022-12-03 ## 2 P1 40 GER Neutropenia 2022-01-03 ## 3 P2 54 JPN <NA> <NA> ## 4 P3 47 BRA Constipation 2022-eleven-29 ## 5 P4 NA <NA> Tachycardia 2022-01-27 For unproblematic queries—like joining tables—this is probably overkill given {dplyr}'due south interface is so similar to SQL. However, if you lot are a SQL wizard and write more complex queries, {tidyquery} can be a great way to become proficient in {dplyr} as it can actually evidence y'all the translated {dplyr} lawmaking.
show_dplyr( " select dm.id, dm.historic period, ae.term from demographics as dm left join adverse_events as ae using(id) where term <> 'Headache' " ) ## demographics %>% ## left_join(adverse_events, by = "id", suffix = c(".dm", ".ae"), na_matches = "never") %>% ## filter(term != "Headache") %>% ## select(id, age, term) By the style, there's also the {dbplyr} packet which translates your {dplyr} code into SQL. That way you don't actually need to learn SQL in social club to query a database.
In this articles nosotros've covered the four most mutual ways of joining tables and how to implement them in R using {base}, {dpyr} and SQL via {tidyquery}. Armed with this cognition you should be able to confidently merge any datasets you come across in R. If you do get stuck feel complimentary to ask a question in the comments below.
Source: https://thomasadventure.blog/posts/r-merging-datasets/
0 Response to "How To Merge Data Sets In R"
Post a Comment